A large number of Python beginners and both professional and aspiring data scientists swear by code notebooks like Jupyter Notebooks. I also used to worship notebooks when I worked on my data science projects. So why do I, a data scientist, now avoid notebooks? Read on to find out and to also learn what tools I use instead.
NOTE
I am aware that notebooks have made it easier for those who came from other quantitative fields like physics, statistics, and engineering to get into coding. They most likely do not have the same software development background as someone from a software engineering background. My intention is not to gatekeep but to raise awareness of some of the disadvantages of notebooks.
Table of contents
- What Are Notebooks and Why Do I Think People Use Them?
- Why I Don’t Use Notebooks as a Data Scientist
- So What Do I Use Instead?
- Thanks For Reading
What Are Notebooks and Why Do I Think People Use Them?
Coding notebooks are a tool for people to combine code with rich text and images all in one file.
With a notebook, you can write code in code cells and see the outputs of those cells right underneath the cell.
Commonly, these code cells are combined with markdown blocks. The combination of code cells and markdown blocks facilitates an interactive development environment to write code, see outputs, document logic, and tell stories all in one file.
The level of interactivity (especially for data exploration and visualisations), the increased flexibility in documentation, and the supposed ease of use are just a few reasons why notebooks are so popular.
They are also used a lot in beginner tutorials and demos. I can see the appeal of that approach: a learner sees the code and what it outputs, and they can provide a structured lesson to follow. However, this may lead some people to use it as their primary development tool, potentially causing bad software development habits.
Why I Don’t Use Notebooks as a Data Scientist
All that being said, it sounds like notebooks make everything easy. That was what I originally thought when I started my data science journey in 2020:
I can run code, see the outputs straight away, explain what the code is doing with markdown and images, and more. This is so cool!
Almost all of the data science tutorials I used to learn employed notebooks to teach. Naturally, I followed suit. So why did I switch after 3 years of mainly using notebooks for development and data science projects? These are some of the main reasons why.
NOTE
There are other minor issues with notebooks that I won’t be sharing here. These are just some of the important ones. Also, keep in mind that notebooks are useful in some situations, but it’s typically more beneficial to use other tools like plain Python files in the majority of cases.
Using Notebooks in a Proper Project Sucks
Using notebooks for exploratory data analysis is pretty handy. As I said, you can write code to explore the data and see what the output looks like instantly. However, I often see data scientists do whole data science projects in notebooks.
For example, you might see data cleaning steps split up across dozens of cells out of order, with hard-coded values scattered around. That makes it more difficult to transfer it into a reliable and intuitive data-cleaning pipeline. I know that there are tools that convert a notebook into a Python file like Visual Studio Code’s notebook editor, but you still need to dig into the code, move lines around, extract hard-coded values, stitch parts together, ensure everything runs in the right order, and so on. I’d rather not have to do that; thank you very much.
It’s also common to see everything in the project, from reading the data to model building, all in a single notebook that’s like 500 cells long or something similar. “Ummm, how do you expect me to deploy that into production or maintain that?”
Using notebooks makes it easier to forget basic software engineering best practices like easy development to deployment processes, modular project components, and not having one thing (in this case, a notebook file) have too many responsibilities.
Notebooks are Stateful
One of the most annoying aspects of notebooks is that it remembers the system’s state.
TIP
This pretty much means that all variables and definitions are remembered throughout the lifetime of the kernel until the cells that assigned them are run again (overwriting them) or if the kernel is restarted (the state is lost).
This causes frustration, especially for prototyping where the code changes quickly and frequently. It is way too easy to get the wrong results or bugs to appear if you forget which cells have run before and the values of every variable.
Another situation that occurs more often than you’d think is when a cell is modified but not run. This leads to the false impression that cells that run in the future will be affected by the changes or that the output of the code cell came from that update and not the previous code.
All these lead to a not very scientific data science project. On the other hand, every time you run a Python file, the state is wiped clean. Therefore, you know that the only cause of bugs is the actual code and not the state. This confidence reduces the mental burden significantly during development, allowing you to worry about what’s important. For beginners, this is a huge win.
Best Practices? Never Heard of Her
Continuing on with the ideas explored in the previous two points, with notebooks, it’s easy to develop bad habits or ignore good habits. I strongly believe that even as data scientists, we should be following software development best practices. However, typically notebook-based projects aren’t modular nor very robust, and the use of cells discourages the use of good coding habits like writing functions, classes, using inheritance, etc. Overall, the code quality due to using notebooks is typically poorer.
One major aspect of software development is testing. Making sure that code works as expected and does not break is very important. Notebooks don’t allow for easy testing that data science project written as modules and libraries can.
There are also a lot of software development basics that get lost when people primarily use notebooks. Topics such as version control, linting, formatting, software design patterns, virtual environments, using the command line, and more are typically abstracted, or the opportunities to learn about them don’t arise when only using notebooks.
Stop Ruining My GitHub Repo Language Distribution!!!
This one is a bit of a joke, but it has always annoyed me. I could write five thousand lines of Python code and push that into a GitHub repo. BUT AS SOON AS I ADD ONE IPYNB FILE WITH ONE CODE CELL CONTAINING A SINGLE PRINT FUNCTION MY REPO BECOMES 99.999999% JUPYTER NOTEBOOK???!!!?! HUHHHH????!?!?!?!?!?!?!
Obviously, that was an exaggeration, but it does makes me that angry.
So What Do I Use Instead?
The vast majority of the time, I write my data science in plain Python or R script files using Neovim, which I then execute through the command line. This allows me to use the Vim motions, Neovim’s customisability, and my configured plugins for my data science.
Now, I’m not telling you that to do data science efficiently, you need to use Neovim. You should use the text editor you’re most familiar with. For me, that’s Neovim; for you, it may be VSCode, sublime text, or something else. The main point is that you should use Python or R files instead of code notebooks.
However, you may be asking the following:
What if I still want to be able to run bits of code interactively and see the outputs?
That’s when you combine the plain Python or R file with a REPL. I use Vigemus’ iron.nvim in Neovim to send bits of code at a time, like I am demonstrating below:

TIP
My whole Neovim configuration can be found in my GitHub repo. I might make a blog post on it in the future.
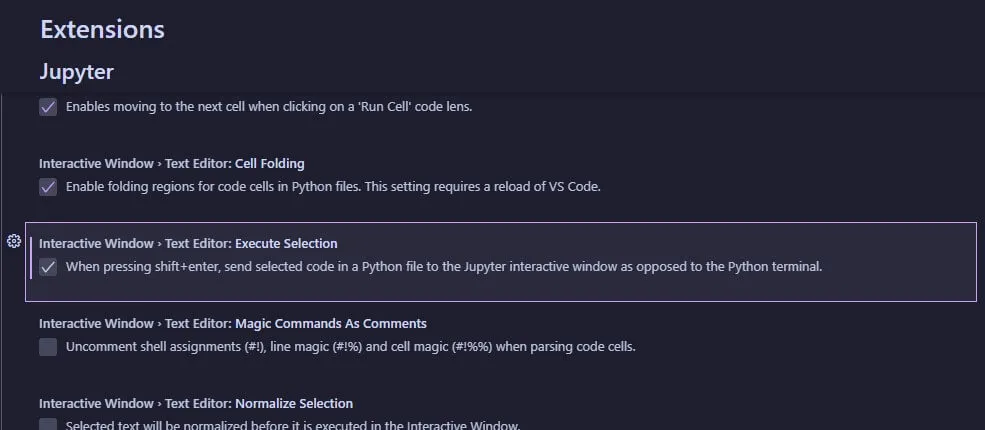
The same thing can be done in VSCode by activating a Jupyter setting and using shift+enter to send the code over to the REPL.
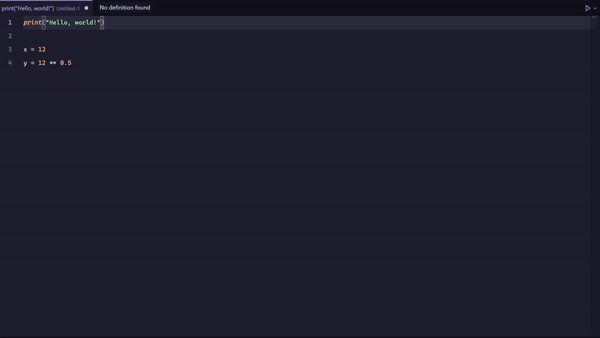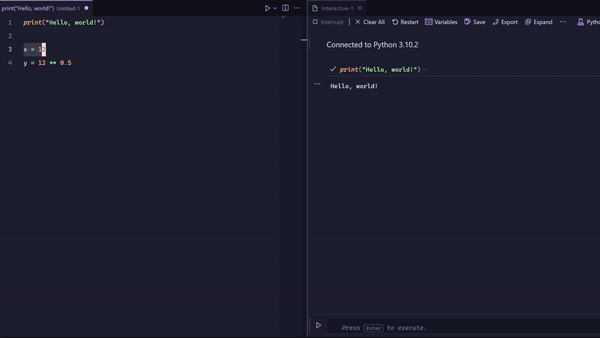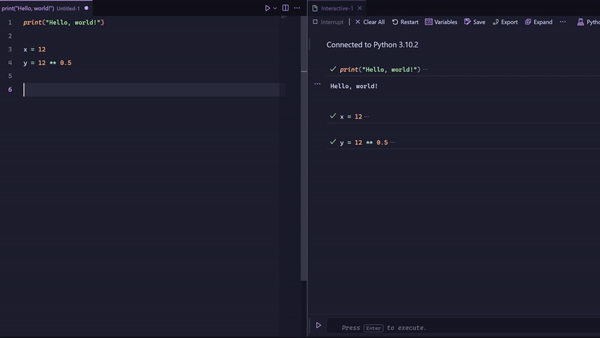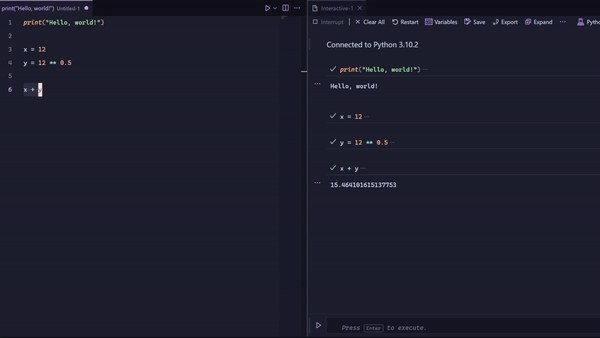
But is that not the same as using a notebook?
Not quite. The main differences are that you are writing in a normal Python or R file, giving you all the inherent benefits of using a code file, and that the history is linear. You can see the exact order you ran the code from top to bottom. This makes it way easier to follow the state of the program and is a way more intuitive way of programming.
Thanks For Reading
Thanks for making it this far. I hope I’ve convinced you to reconsider using notebooks so often from now on. If you disagree with some of my points, feel free to let me know by emailing me. I am keen to discuss the topic more and maybe if you’re convincing enough, I might even end up believing notebooks are the greatest thing ever created.
Lastly, check out Joel Grus’ talk on why he doesn’t like notebooks. Joel goes through some of the topics I discussed and more in an entertaining and hilarious presentation. I highly recommend it!